TenserFlow란?
TenserFlow에 대해 간단히 소개하면 구글에서 제작한 오픈 소스 기계학습 라이브러리이다. 일반인들이 활용하기 쉬우며 Python 언어를 사용한다.
개발환경과 목표
Colab에서 코드를 작성할 것이다. Colab은 별도의 설정 없이 웹 상에서 Python을 사용할 수 있으며, 구글에서 CPU와 RAM를 제공하기에 자신의 컴퓨터의 사향과 상관없이 프로그램을 실행 할 수 있다.
colab.google
Colab is a hosted Jupyter Notebook service that requires no setup to use and provides free access to computing resources, including GPUs and TPUs. Colab is especially well suited to machine learning, data science, and education.
colab.google
이 Colab에서 간단한 예측 AI를 만들것이다.
예제) 온도에 따른 레몬에이드 판매량 예측
예제)
데이터
AI를 학습시키기 위해선 데이터가 필요하다.
다음과 같은 csv 데이터를 활용할 것이다. (엑셀로 csv 파일을 만들어도 상관 없음)

추후 결과 값이 얼마나 정확한지 판단하기 위해, 온도가 증가함에 따라 판매량이 2배씩 증가하도록 데이터를 작성하였다.
코드
먼저 TensorFlow와 CSV 파일을 읽을 수 있는 pandas를 불러오자.
|
1
2
3
4
5
6
|
import tensorflow as tf
import pandas as pd
lemonade = '/content/레몬에이드.csv'
data = pd.read_csv(lemonade)
data.head()
|
cs |
이후 lemonade에 csv의 파일 경로는 넣고, data에 lemonade을 저장하게 한다.
파일 경로는 파일을 Colab에 드래그해 넣고, 우클릭 후 경로 복사를 누르면 된다.

온도에 따라 판매량이 변화하게 된다.
즉, 온도는 독립 변수이며 판매량은 종속 변수이다.
|
1
2
3
|
#독립 변수에 의해 종속 변수가 변함
독립 = data[['온도']]
종속 = data[['판매량']]
|
cs |
독립에 data의 온도 부분을 저장하고, 종속에 data의 판매량 부분을 리스트 형태로 저장한다.
(data는 위에서 레몬에이드 정보를 담은 것)
이후 AI 학습을 위한 설정을 해야한다.
|
1
2
3
4
|
X = tf.keras.layers.Input(shape=[1]) # 1은 독립변수 개수
Y = tf.keras.layers.Dense(1)(X) # (종속변수의 개수)(독립변수)
model = tf.keras.models.Model(X, Y)
model.compile(loss='mse') # loss = '손실함수'
|
cs |
손실 함수는 딥러닝 모델을 학습할 때 오차값을 계산해주는 함수로 여러 개가 있다. (mse, rmse, mae 등등)
이제 딥러닝 모델을 학습하게 하면 된다.
|
1
|
model.fit(독립, 종속, epochs=100)
|
cs |
여기서 epochs는 학습의 횟수를 말한다.
학습의 횟수가 증가하면 일반적으로 정확도가 올라간다.
위의 코드를 하나로 합치면 다음과 같다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
import tensorflow as tf
import pandas as pd
lemonade = '/content/레몬에이드.csv'
data = pd.read_csv(lemonade)
data.head()
#독립 변수에 의해 종속 변수가 변함
독립 = data[['온도']]
종속 = data[['판매량']]
X = tf.keras.layers.Input(shape=[1]) # 1은 독립변수 개수
Y = tf.keras.layers.Dense(1)(X) # (종속변수의 개수)(독립변수)
model = tf.keras.models.Model(X, Y)
model.compile(loss='mse') # loss = 손실함수
model.fit(독립, 종속, epochs=100)
|
cs |
이를 실행하면 설정한 epochs 횟수 만큼 출력문이 생성된다.
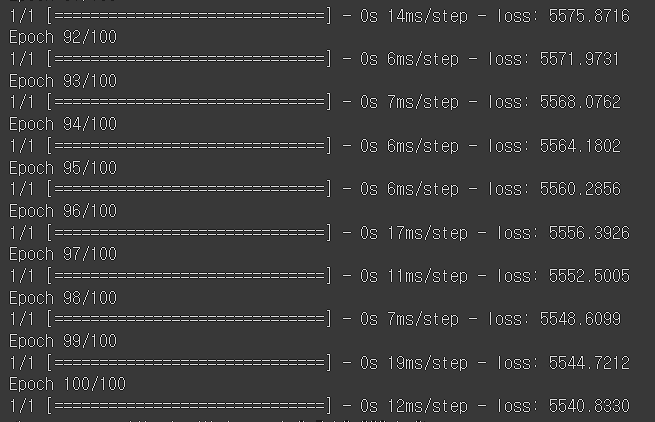
여기서 loss가 매우 중요한 지표이다.
loss 값이 0에 가까울수록 정확도가 높다는 의미이다.
loss 값을 줄이고 싶으면 학습의 횟수를 증가시키면 된다.
이제 학습된 모델은 준비가 되었다.
그럼 예측을 해보자.
|
1
|
model.predict([[20]])
|
cs |
predict 함수에 예측하고 싶은 값을 넣으면 된다.
초기 데이터를 제작할 때, 온도의 2배가 레몬에이드의 판매량이라고 가정하였다.
즉 40에 가까운 값을 예측해야 한다.
다음의 표는 학습 횟수에 따른 예측 값의 변화이다.
(값은 개개인의 환경에 따라 다를 수 있음. 온도 값은 20으로 고정함)
| 학습 횟수(epochs 값) | 예측 값 |
| 10 | 9.068099 |
| 100 | -31.614763 |
| 1000 | 24.698929 |
| 10000 | 40.01065 |
학습 회수가 10000번일 때, 40과 비슷한 값이 나왔다.